2018年振り返りと来年の展望 事業家へ踏み出していく年にしていこう
2016年も振り返りを行っていましたが、今年の振り返りをしようと思います。
昨年の2017年は、マラッカにて、寺でポップダンスを踊るおばさん達を横目に、ちょっと風邪気味のおっさんと二人で年を越したので、振り返りができませんでしたが、今年は日本でゆったりしているので振り返ろうと思います。
サマリー
サマリーは以下
- 社会人3年目になり、やっと社内外で少しずつ成果が出始めた年だった
- 海外を蹴って職種を変えることを選んだ
- 労働集約型のお金の稼ぎ方から抜け出す実験がうまくできてきた
- 来年は更に「事業家」と言えるような人になる年にしていきたい
今年の振り返り:社内外で成果が出始めた年
社内で表彰&自分がやりたいところは達成
今年は社会人3年目といういわゆるそれっぽい区切りの年であり、個人的に裏で管理している目標において、
「大きな結果を出す。マーケター5年以内の先輩を含めトップの結果を出す。圧倒的な結果で実績を作る。」
みたいに掲げていた年でありました。
ぶっちゃけよくそんな目標を掲げたなぁと思いつつも、悪くない程度には達成できたかなと思います。全社のマーケティングという単位で、表彰をいただき一応全社初の取り組みをやり成果を出したことが認められました。
でも別にそんなすごいことをしたわけではなく、一年目のときにイメージしていた、よくわからない何かしらの想像と比べると、大したことはない気はしています笑
レジュメに書きやすいような実績が一つ作れたので、個人的なキャリアには非常にポジティブだと思いますし、このような機会をくださった周りの上司などには本当に感謝しています。
自分の中で、データサイエンス×マーケティングみたいなことをし、結果を出す。
ということはマーケティングの部署にいるときにやっておきたい。と強く思っていたので、そこを一旦達成するまで突っ走れたのは非常に良かったです。
海外を蹴って、職種を変えた新たな道へ
当初の想定だと、今頃か4月辺りから海外に2〜3年とかのスパンで働いている予定でした。
でも、マーケティングという職種では行けるがそれ以外の職種を経験せず海外に行ってしまうと、マーケのスペシャリストになってしまい、僕が目指す方向性にはうまく向かっていけないのでは? と感じ、海外を蹴って、職種を変えることを選びました。
なぜ変えたかについては以下記事に詳細は書いています
ウェブマーケターからUXデザイナーに転向しました。その理由と今後の展望 - 世界を目指すIT少年の学習記録
後述しますが、今働いている会社は副業が認められているということもあり、わりと社外を手伝うとかも可能だったりします。そういった中で、マーケティングという職種は、あくまで全体の中の一部であり、代替可能であるというような気がなんとなくしていました。
もちろん、いくつかの役割の中でも最も重要な要素に並べられるくらいのものではあると思っていますし、実際アメリカの起業家の先生には、「ファイナンスやマーケティングなどいろいろある中で、マーケティングが最も重要だ」といった言葉を聞いていたので、それくらい重要なのではとは思っています。
社外では労働集約からの開放の一歩を踏み出した
1年目あたりのころは、社内では信頼度が低く(わけわからないこと言っていたし、実際しょぼかったから)あまり自分がやりたい!と思えるようなことをできませんでした。
そのため、社内でできないことは社外でやっちゃえ的な精神もあり、いくつかのスタートアップと関わり、そこで副業的に手伝っていることが多かったです。
ただ、そこで感じたのは3つありました。
- コンサルとか代行みたいなのはしんどい(労働集約isしんどい)
- 契約も突然打ち切られたりなど、外部要因が大きいのでコントロールが難しい
- マーケってなんだかんだ一つの機能なんだ
3については部署異動をしたきっかけの一つになったものですが、1と2が個人的には良い発見でした。
社外でできないことをやれるのは楽しいものの、お金を安定的に稼ぐみたいな観点でいうと、やはり労働集約はわりときついです。
うまく仕組み化できればコンサルとかも安定収入&しんどくなくできると思いますが、個人的にはそれをすることは本質的ではなくなにか価値を生み出しているかでいうとそうではない気がしてしまいました。
そこで、ある時から、本当に面白そうな案件でない限りは受けないで、自分の事業を育てることに注力しよう。
と決めました。
メディアに注力することを決め、成果がうまく出始めた
そもそもマーケ担当がなぜ雇われるかでいうと、雇っても事業がよりお金をもたらすから雇うわけです。
であれば、自分で事業を作ってしまい、自分でマーケすればその分のお金が全部自分に入るわけですから、自分の事業のCMOになる方が圧倒的に良いはずだと思いました。
そこでマーケと親和性の高いメディアをはじめました(集客≒収益になるため)
はじめは、とりあえず儲かりそうな領域を選定し、やりはじめましたが、
びっくりするほどモチベーションがわかない
ということが起こりました。
前からわかっていたのですが、ただお金が儲かるということには関心がわかないタイプで、これをやることによって世の中がよくなる。だったり、誰かが喜ぶ。みたいなところがないと自分は機動力が出ません。
ですので、もはや儲からなくてもいいから自分がやりたいと思える領域で、ちゃんとビジョンにしたがって運営しよう
というマインドに切り替えました。
結果、メディアとしては以下のグラフのように比較的順調に成長しており、かつ自分がなるべく働かずに外注をするというスタイルで、うまく回っております。
きちんとやり始めたのが5月なので、そこからは順調に伸びています。成長率でいうと週に10%以上の成長

このような取り組みは労働集約型から一歩出る取り組みになったのではないかと個人的には感じています。
現状このメディアもちょっと伸び悩んでいる部分もあるので、いろいろ考えて変えてはいます。
来年の展望
1.個人事業主として事業家へ一歩踏み出していき事業をより先へ
上記のメディアがそこそこ収益を生んできたので、やっとこさ個人事業主になります。
2019年1月からなるので、きちんと会計などもやったり、節税対策できるところはしたりと思っています。
また、2019年はこのメディアはある程度軸にしつつも、新たなビジネスモデル(集客≒収益ではないもの)も模索し、更に進んだ価値を顧客のもたらすようなことをしたいと思っています。
このメディアにも新たに機能を追加したりしますが、それとは別で、自分でPythonベース(Django)でアプリケーションを作ってやっていこうと思っています。
自分がやりたいと思える領域で、ちゃんとビジョンにしたがって運営
これさえ守れば、僕は続けられるし、続けることが結果につながるので、その思いでやっていきたいです。
今までは一人×外注がメインでしたが、今後は、複数人の仲間とでっかく
も視野に入れて頑張ってみる年にもできたら嬉しいなと思っています。
2.UXとしてのプロを目指す
ウェブマーケターからUXデザイナーに転向しました。その理由と今後の展望 - 世界を目指すIT少年の学習記録
で言っているように
「ABテスト屋さんではなくて、本当のサービス全体を見れるCXO的役割」を目指すにあたり、きちんと自分はUXのプロなんだと言えるような知識と経験を積んでいきたいと思っています。
インプットすることやコンスタントに勉強することはある程度できるので、きちんとインプットを続けていこうと思っています。
3.リーダーシップをより強く、より幅広くよりBigに
主に社内ですが、リーダーシップを持ってプロジェクトを推進していく。という力は結構ついてきた気がします。
よりビジネスもテクノロジーでも幅広く深く、リーダーシップを持って推進できるようにしていきたいと思っています。
社内で学んだことは、社外でも存分に発揮し、
複数人の仲間とでっかく
をやっていきたいなと思っています。
Go Big or Go Home!
Appendix: 今年学んだことや読んで良かった本など
最後に今年読んだ本や学んで良かったものを取り上げます
学んで良かったもの
Text Mining and Analytics
僕が大学時代に留学していたUniversity of Illinois at Urbana-Champaignが提供しているテキストマイニングのコースです。
今まで自然言語処理はなかなかハードルが高く、トライしていませんでしたが、これを受けてみました。
現状どういうことができているのか、どういう考え方をするのかとかがわかり非常に有意義でした。
所感では、やはり画像認識とかと比べてまだまだ進んでいない領域なんだなぁって感じでした。
Build Fiverr marketplace with Python Django and Braintree
FiverrというアメリカのクラウドワークスみたいなものをDjangoを使って実装してみよう!というものです。このcode4startupは非常に実践的なものが多く勉強になると思います。
本

UXを学ぶならまずはこの一冊!と進められて読みました。これは本当に最高の一冊の一つだと思います。リーンスタートアップなどの概念もありますが、リーンの概念のユーザーインタビュー系は基本UXの概念の一部に内包されるようなきがしました。
")
面白かったです。自分の一歩先を行く人という感じで、非常に良い本でした。
すごい素直で素敵な方だなと思いました。
")
10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く (Informatics &IDEA)
- 作者: 青木峰郎
- 出版社/メーカー: SBクリエイティブ
- 発売日: 2015/06/30
- メディア: 単行本
- この商品を含むブログ (7件) を見る
最近はSQLやTableauを駆使することが増えたので、これをきちんと理解できるようにしました。

この本はより上記の本の発展的な本で、上記の本レベルの基礎知識がないと厳しいです。社内の同僚の方が書いた本で、その方からいただきました。
2019年はこの日記を定期的に振り返って、自分を鼓舞して目標に向かっていけるようにしたいです。
今年も多くの方に本当にお世話になりました。来年もどうぞよろしくおねがいします!
ウェブマーケターからUXデザイナーに転向しました。その理由と今後の展望
10月から会社は変更しませんが、ウェブマーケターからUXデザイナーに転向することになりました。
名称としては、UXデザイナーですが、実際にやることはスクラム開発でいうProduct Ownerだったり、ディレクターとか呼ばれるような「何を作るかを定義する人」です
役割としては「よりサイトの体験をよくし、その結果事業に貢献する」という役割になっています。主にやることはABテストなどがメインですが、サイト自体に手を入れる職種への変更となります。
なぜ、転向しようと思ったか、その理由と今後何をしたいかを自分のメモがてら綴ります。
目次
なぜ転向しようと思ったか

理由は主に2つです。
1. 現状の環境に満足していたので、あえて難しい方向へ行くべきだと思った
2. もしかするとよりUXが本質的なのではと思っている
からです。
理由1:現状の環境に満足していたので、難しい方向へ飛び出るべきだと思った
正直、今の職種も部署にも超絶満足していました。
メインはウェブ広告を媒介にした集客でしたが、おそらく日本国内でもトップクラスの金額を動かす経験や、20人弱のプロジェクトのリーダーみたいなのもやらせてもらったり、半年に一回くらいは海外出張行かせてもらえたり、
職場の環境も良くてホワイトだし、周りの人はみんないい人だし、給料もよいし、評価も適切にされているし、自分もパフォーマンスを発揮できているし、、、etc
って書くと、え、じゃあ今のままでいいじゃんって話かと思うんですが、
まだ三年目なんですよね(驚)
これが引退間近の50〜60代のおっちゃんなら、いっちょあ上がりでいいんです。
けど、三年目のペーペーがこんなに心地良く感じていたら問題なんですよね。
これが一番の理由でした。
今まで振り返っても、あえて厳しい状況へ飛び込むときに自分は成長したし、そういうときに一番やりがいを感じていたので、転向するのが適切だと判断しました。
あと、マーケターとしてやってみたかったことは達成できたので、区切りがついたというのも一つあります。
入社してから、50歳になるまでキャリアパスみたいなのを描いているのですが、その中で3年以内に達成したいと思っていたデータサイエンスとマーケの融合みたいなのを達成できたので、まあ区切りついたなと。
乗りに乗っているぜ!みたいなタイミングこそやめどきなんだろうな的な、安室ちゃんみたいにね
基本属性はスポーツ少年なので、やっぱりうまくなったり強くなるには、常に自分が難しいと思うことにチャレンジし続けたり、筋トレのウェイトの負荷を上げ続けないと人は成長しないですからね。
一回くらい靭帯断裂するくらいチャレンジしたほうがいいぜ!ってな。(今回の転向は靭帯断裂とかしなそうだから、次は靭帯断裂していきたい)
じゃあUXってそんなに難しいチャレンジなんですか?っていう話なんですが、それが実際難しいと感じたんですね。
なんで難しいかなと思ったかというと、副業として60万PVくらいのサイトを縁があって運営していました。(CSとかまで含め開発以外は全部)
サイトは、いわゆるユーザーが自分たちで作るUGMってやつです。(副業申請通っているので、公言無問題だが、具体的なサイト名は書かない)
そのサイトを日々改善を行っていく中で、
思ったとおりにユーザー行動が変容しない!
良かれと思って改修した機能に対してユーザーから不満をあげられる!
などが結構発生しました。
そこで明らかに、UXってむずい。ユーザーの行動を変容させるのってむずい。ユーザーが本当にもとめているものを探るのってむずい。って強く思いました。
だからこそそこに向き合っていきたいと思ったりしました。
※別件ですが、CSの大事さもそのサイトを通じて実感しました。CSとUXや開発は組織として、密に接合すべき
理由2:(もしかすると)より本質的な役割なのではないかと思っている
にわとり卵問題という問題があります。
にわとりが先か、卵が先か、どっちもないと始まらないからどっちから始めるべきかわからないみたいなやつです。
マーケ(集客)とUX(サイトの質)もにわとり卵にすごい似ていて、
・集客できてもサイトがイケてないと穴の空いたバケツ
・サイトがイケていても、誰も来なかったら意味ない
みたいなのがあります。
前者は大企業に多く、後者はスタートアップに多いかと思います。
どっちも切っては切り離せないくらい大事ってことですね。
じゃあ、再度にわとり卵に戻ると、どっちがより重要かでいうとにわとりだと僕は思います。
なぜって、卵だけあっても孵化しないし、孵化しても鶏になる前に死ぬから。
でもにわとり先にいれば、卵産めるかもだし、卵孵化できるので、なんだかんだにわとり大事じゃね。って思っています。
マーケとUXでいうと、より大事なにわとりはUXかなって思っていて、
前提、マーケがある程度できている場合はですが、最終的にユーザーが愛してくれるような最高のサービス体験を作り出すことが、最強の競合優位性なのではないかと思っているからです。
例えば、Instagramってもはやマーケいなくてもほぼほぼユーザーは毎日使ってくれますよね?
まだ新規獲得とか、ブランディング目的でのマーケはやっているかもですが、集客っていう目線は非常に小さいと思っています。他にも、AmazonとかもECの中ではそれに近しいし、Googleもそうですよね。
また、ウェブマーケの世界ではSEOとかからSXOという話がでてきていて、SXOとはSearch Experience Optimizationの略かな?で、何かでいうともうGoogleのアルゴリズムが高度になりすぎて、手先のテクニック効かないから、サイトのエクスピリエンスをより良くするしかなくない? みたいな話が出てきています。そういう流れも、今後よりUXに寄っていく一つの流れかなと思っています。
今後やりたいと思っていること

今後やりたいと思っていることはサラッと。
ABテスト屋さんではなくて、本当のサービス全体を見れるCXO的役割
本当のUXデザイナーって、ABテストに勝ちまくる人ではなく、サービス全体をよくすることにコミットできる人です。
UXの話でよく出てきますが、UXってサイト上での行動に限らず、サイト外やサービス全体の設計をよくすることが最終ゴールです。
そうなると、今後より必要になるのは、集客からサイト改善からブランディングからCSから上流から下流までわかって設計できるようなCXO(Chief Experience Officer)みたいな人じゃないかなって思っています。
ので、そのような人を目指すことをゴールにしています。
Data driven&User centered デザイナー
UCD(User Centered Design)という言葉は結構一般的だと思いますし、ユーザーを中心にすることが前提というのはUX界では当たり前なんだろうなという風には思っています。ただ、定性的観点も結構多いなと思っているので、データ・ドリブンでさらに仮説を強くすることができたらめっちゃ強いんじゃないかなって思っています。
SQLとTableauやJupyterなどを用いて、定量的に分析したり、場合によっては機械学習アルゴリズムで特徴量抽出したりみたいなのまでできたらすごい強いですよね。
おそらく今後はUXの世界にもデータサイエンスとの融合みたいなのも広がっていくと思っています。
実際、あの
IDEOもデータサイエンス集団を買収しコラボしたり(Using Data Science to Design Human Connection | ideo.com)
データサイエンティストがプロダクトマネージャーになったり(Why good data scientists make good product managers (and why they’ll be a little uncomfortable)
)、Airbnbはデータ分析基盤をきちんと構築したり(Experiments at Airbnb – Airbnb Engineering & Data Science – Medium)
など世界的な動きが見えてきています。
その、流れを組んで自分もUser Centeredを持ちあわえたData DrivenなUXデザイナーになりたいと思っています。
さあ、UXの勉強もめっちゃしなきゃ。笑
今は、IAに関する良書だという↓の本を読んでいます。
")
理解の秘密―マジカル・インストラクション (BOOKS IN・FORM Special)
- 作者: リチャード・ソウルワーマン,Richard Saul Wurman,松岡正剛
- 出版社/メーカー: NTT出版
- 発売日: 1993/04
- メディア: 単行本
- 購入: 5人 クリック: 63回
- この商品を含むブログ (36件) を見る
Tinderで自動で100件いいね押すプログラム書きました笑
表題の通りです。
「 退屈なことはPythonにやらせよう」という本

退屈なことはPythonにやらせよう ―ノンプログラマーにもできる自動化処理プログラミング
- 作者: Al Sweigart,相川愛三
- 出版社/メーカー: オライリージャパン
- 発売日: 2017/06/03
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (5件) を見る
の中で紹介されている、Pyautoguiというライブラリの機能でできます。
まずは、どんな感じになるかが以下のGIF画像です。
ちゃんといいねがどんどん押されていますw
なかなかシュールで、笑いましたw
以下がコードです
#ライブラリをインストールしていなかったら、初めだけ行う
pip install time, pyautogui, webbrowser
#あとは以下を走らせるだけ
import time
import pyautugui
import webbrowser
url='https://tinder.com/'
webbrowser.open(url)
time.sleep(10)
i=0
for i in range(0,100):
i+=1
pyautogui.click(449,706); #Tinderのいいねの位置をpyautogui.position()で取得してから
time.sleep(0.5)
pyautogui.position()でTinderの画面内のいいねボタンの位置を取得します。
pyautogui.position()
とうつと
(449,706)というようにポジションが表示されるので、その 値をpyautogui.click()に入れるだけです。
以上
自動化って面白いですよね。
※Pythonまだダウンロードしていない人用
Pythonの環境がない人は
Anacondaをダウンロードすると使えるようになります。
上記プログラムは、アナコンダのコマンドプロンプトみたいなやつで、pythonと打ち
>>>
という表示がでたらコピペするだけです。
Macならターミナルから直接
Adtech NY 2017に参加して感じたマーケティングの未来
このブログではデータサイエンス話ばっか書いてますが、実は本職はウェブマーケターなので、今回はウェブマーケティングに関することを書いてみます笑
11月はじめに、会社の出張でAdtech NY 2017に参加してきました。
↓これがホームページ
その中で今後のマーケティングの流れ、マーケターとして何を習得するべきかを色々感じたので文章にしてみます。
目次
- Adtech NYとは?
- ラストタッチモデルの終焉
- マーケティングは局所的から、統合的マーケティングの時代へ
- 統合的マーケティングに必要なのは人間中心の考え方
- 最後に 一緒に何かやりたい、勉強したい、コラボしたい人いたら気軽にメッセとかください!
Adtech NYとは?
Adtech NYとはWikiによると以下↓
ad:tech is an international series of digital advertising and technology conferences and exhibitions for the interactive marketing profession. ad:tech hosts events in New York, San Francisco, London, New Delhi, Shanghai, Singapore, Sydney, Melbourne and Tokyo. The events are produced by ad:tech Expositions, LLC, which is owned and operated by DMG Events, part of Daily Mail and General Trust.[1][2]
Conference panels and educational sessions address a range of relevant subjects: online advertising strategy, performance-based marketing, emerging advertising platforms, integrated marketing, social media, search, mobile, analytics and brand marketing. Shows have a combination of high-profile keynote speakers, topic-driven panels. and workshops.
つまり、NY, サンフランシスコ、ロンドン、ニューデリとかいろいろなところでやっているマーケティングのプロフェッショナルのためのイベントです!
と言っております。
最近は東京でもありましたが、東京のセッションよりNYのセッションのほうが最先端的だったと感じております。
Adtech NY会場の雰囲気
会場はNYのマンハッタンの中心にある
Metropolitan Pavilionという場所でした。
普段の雰囲気はこんな感じ↓でちょっとクラブ感があります笑

実際行ってみたら、何故か展示会会場の中央にDJがいて回していて、
「なんでやねん!」って突っ込みましたねw
シカゴの大学にいたときを思い出しましたね笑
↓これが実際のスタート ペンシルベニア大学Whartonスクールのマーケティングの先生がファシリテーターとして紹介するスタンスでやっていたりしました。

登壇者は結構色々な分野の人がきていて
事業会社は、Microsoft, Google, Hilton, トゥーミーとかマクドナルドとか
代理店とか広告に特化しているところはちらほらで主に展示会のところにいる程度(MailChampとか)
あとはマッキンゼーとかもいましたね
今回のメインテーマ
この3つでした。Ad Fraudについては、あまり興味がないのでさくっと書きますが、
日本語だと広告詐欺といって「本来のターゲット以外のユーザー(自動ボットや雇った人とか)によって偽装の広告クリックを生み出すこと」です。
詳しくは
あなたも騙される?アドフラウド(AdFraud)を3つの論点で徹底解説! | エビスマーケティングカレッジ-EBIS MARKETING COLLEGE
とか読んでみてください。
今回はメディア運営者向けにAds.txtというものが紹介されており、それがゲームチェンジャーになりうるぜ!Yeahみたいな会話がされていましたが、広告主側は関係ないです。
それでは本題の、ラストタッチモデルの終焉そして統合的マーケティングについて
ラストタッチモデルの終焉
そもそもラストタッチモデルとは?
実務でやっている人はご存知だと思いますが、
「コンバージョン(購入とか)をどのチャネルから流入したものの成果とみなすか?」
が結構重要です。
なぜ成果をはからなければいけないのかといえば、マーケティング施策の効果がわからないし振り返りできないからですね。
例えば、100万円広告かけてそれに対してどれくらい購入されたか?どれくらい売上があがったか?を明確にしなければいけません。
100万円使ったのに売上10万円だったら90万赤字ですし、200万円売上上がったら100万円黒字なのでまだまだ広告使えるぜ!ってなります。
で成果をはかるときに問題になるのが、「アトリビューション」という考え方です。
アトリビューションとは、配分と日本語訳できますが、前述のどのチャネルの流入を成果とみなすかの議論をする際に重要になります。
具体例を示しましょう。
例えば、求人サイトを運営しているA社は、「データサイエンス 求人」という検索キーワードに対して広告を出しているとします。A社はSEO対策もしているので「データサイエンス 求人」と検索するとサイトのURLが検索画面に出てくるとしましょう。
あるユーザーBさんが、「データサイエンス 求人」と調べたときに、
一番上に出てきた広告をクリックしてサイトを訪問したとします。今までこのA社のサイトのことを知らなかったのですが、使いやすそうだなと思い、会員登録をして、いくつかお気に入りに登録しました。
数日後、ユーザーBさんは再び「データサイエンス 求人」としらべてSEO流入でA社のサイトに訪問したとします。そこで先日登録していたお気に入りの中から一社に応募するとします。
A社のサイトは応募したタイミングでお金を貰えるモデルだったので、そのタイミングでコンバージョンが発生しました。
整理すると
①「データサイエンス求人」で検索し広告をクリック
②「データサイエンス求人」で検索してSEO流入でサイト訪問しコンバージョン
という図です。
この時、
ラストタッチというアトリビューションをA社が選択していた場合は
ラストクリックという名前が示すように、「最後のタッチポイント」に成果がつくわけですね。
はじめて認知したのは広告にもかかわらず、広告の効果は評価されないわけです。
でもおそらく、はじめて認知したのは広告なのだからおそらく広告についてもある程度評価すべきだよね。というのが普通の考え方でしょう。
しかし、色々とテクニカルな理由から今まではそれぞれのチャネルを考慮するのが難しいのが現実でした。
ラストタッチからマルチタッチそしてDDAへ
上記のようなラストタッチをモデルとした評価だと、本来評価されるべき他のタッチポイントが過小に評価されてしまう。という問題がありました。
そこで、ラストタッチ以外も加味する「マルチタッチ(複数のタッチポイント)」を評価しよう!というのが徐々に進んできました。
日本ではほとんど(おそらく90%以上)がラストタッチを採用していると思いますが、
AdTech NYでのセッションによればなんと「3分の1がマルチタッチを採用している」との発表がありました!!
ここでマルチタッチの難しさを考えましょう。先程の例のように「広告→SEO→コンバージョン」というような二点しかなければ話は簡単です。
それが、「広告→広告→SEO→SEO→コンバージョン」とか「広告→SEO→メルマガ→コンバージョン」というように無数のパスが考えられるわけです。
パスの数=チャネル数^タッチ数
というようにタッチ数の累乗で増えるNP問題となります!現代のコンピュータで解決するのが難しいのは納得感があるかと思います。
※NPとは、現代の古典コンピュータ(量子コンピュータではないコンピュータのこと。スーパーコンピューターを含む)では解くことができない数学的な計算領域のこと
ここに対して、データでアトリビューションを考えようというアプローチ
通称DDA≒Data driven attribution(データドリブンアトリビューション)
というのがGoogleなどによって発展してきました。
以下の図がわかりやすいですね
次の概略的な例では、オーガニック検索、ディスプレイ、メールの組み合わせでコンバージョン確率が 3% になっています。ここからディスプレイが抜けると、確率は 2% に下がります。ディスプレイが介在した場合に 50% の上昇が見られるという結果になり、この値がアトリビューションに使用されます。
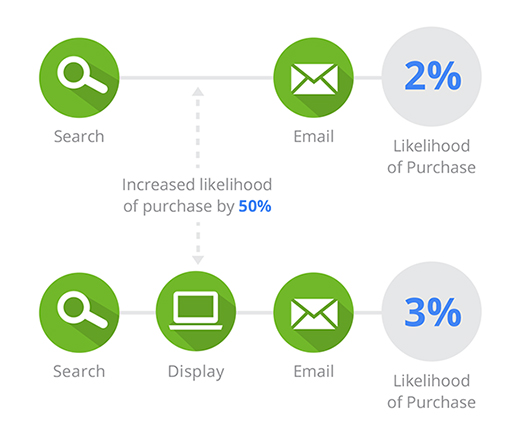
このようにラストタッチ以外の値をいい感じに計算してDDAを作成します。
※Googleはシャプレー値という値を元にDDAモデルを作成するそうです。
シャプレー値という貢献度の測り方 - 3日で学ぶ交渉術!ゲーム理論入門
Google以外にもAdobeなどの各社がDDAには取り組んでいて、日本の企業でベイジアンネットワークを用いてみたいな会社もありましたが、なかなかトラッキングの問題などもありうまくいかないのが現実でした。
具体的にDDAをどのように計算しているかは不明ですし、NP問題だから厳密解ではなく近似解なんでしょうが、実務レベルで成果が出るものが先日公開されていました↓
www.ja.advertisercommunity.com
個人的にはデジタルマーケティングの次の時代の到来を感じました。
さらに、ウェブに限らず、オフラインデータ(SalesForceでの営業とか)のデータともコラボできるようなリリースが発表されていて、すごい楽しそうな時代だーと勝手にテンションが上がっていました↓
マーケティングは局所的から、統合的マーケティングの時代へ
ラストタッチからマルチタッチへ変わった世界
このようにテクノロジーの発展(トラッキングやモデリングの発展)によって、本来あるべきマルチタッチでの成果を加味する時代が到来しつつあり、実際それにむけて進化していなければなりません。
先述のように、欧米では3分の1もマルチタッチモデルを採用していてその中でいかに戦うかというセッションが多かったと感じました。
マルチタッチということは、局所最適に広告担当は広告だけ、SEO担当はSEOだけという世界ではうまくワークしないということを示唆しています。
そのためにはより統合的な、複数のチャネルの影響を加味したマーケティングが必要になってきます。
統合的マーケティングに必要なのは人間中心の考え方
マルチタッチでの統合的なマーケティングの時代に何を重視すべきかの話が今回多かったですが、結局のところ「人間中心」というワードに集約されるかと思いました。
UX的な人間中心設計とマーケティング
おそらくウェブマーケティングではなく、いわゆるマーケティングをしている人は当たり前だと思うのですが、ユーザーの思考(インテンション)をいかに変えるかというのを日々フォーカスしているかと思います。
ウェブマーケティングではテクノロジーな話が多く、その部分が軽んじられることも多々ありますが、今後はカスタマージャーニーなどを重視した人間中心でのウェブマーケティングが重要になっていくと感じました。
詳細は割愛しますが、カスタマージャーニーに似た一つの考え方のモデルとして、マッキンゼーがCustomer Decision Journey(CDJ)というのを提唱していて、そのセッションが非常に面白かったので、興味があればググって読んでみてください。
またカスタマージャーニー視点で考えるマーケティングなども紹介されていました。
あまりカスタマージャーニーについて詳しくなかったので色々勉強したのですが、その中では以下のスライドが実践の中で使うにはわかりやすいように感じました↓
本では以下の本が非常に良かったです。

マーケティングオートメーションに落とせるカスタマージャーニーの書き方
- 作者: 小川共和
- 出版社/メーカー: クロスメディア・マーケティング(インプレス)
- 発売日: 2017/06/26
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
今後のマーケターにはUXは必須。UXを学ぶために
結構前↓
データサイエンス学ぶならUdacityのData analyst nanodegre 11月振り返り - 世界を目指すIT少年の学習記録
からSEO観点とかでもUX大事だよねと思ってはいたのですが、今回それをより感じましたし、必須だと感じました。
別にマーケターにかぎらずウェブに関わる人はほとんど(インフラとかは関係ないかも?)必要だとは思っております。
よしやろう!と思ったらとりあえず一気に始めてみるのが僕のスタンスなので、すでに色々本をあさり読み、実際の業務でも生かしはじめております。
その中で良かった本とかがあったので以下に紹介してみようかと思います。
UX本やら学習のためのリソースについて
まだ学びはじめたペーペーですが、少しは色々読んだので紹介してみようと思います。良書や良いコミュニティあるよとかあれば是非教えてください!m(_ _)m
本
初心者用
おすすめ度:★★★★★
はじめて読むならこれが一番良い気がする。幅広くかつわかりやすい

UXデザインのやさしい教本 UXデザインの仕事の実際、学習のヒントとアドバイス
- 作者: チャド・カマラ,ユジア・ジャオ,保坂浩紀,林れい
- 出版社/メーカー: エムディエヌコーポレーション
- 発売日: 2016/06/30
- メディア: 単行本
- この商品を含むブログを見る
おすすめ度:★★
読み途中ですが、まあわかりやすいっちゃわかりやすいものの活用方法があまりイメージつかない。本人と話したいw

おすすめ度:★★★
日本のHCDの協会?みたいなのが出している。学術感がすごいけど初読みは良いかも。

おすすめ度:★★★★★
ちょっとUXとずれるけどビジュアルデザインってどういう観点で構成していくかがわかって面白い。UX的観点もやはりふくむんだなぁって思った

ちょっと深掘りたい人用
おすすめ度:★★★★★
始めて読む本というよりちょっと知ってからの人が良いとは思いますが、何にせよ情報が広い!そして更に学ぶための情報も載っている!

IA/UXプラクティス モバイル情報アーキテクチャとUXデザイン
- 作者: 坂本貴史
- 出版社/メーカー: ボーンデジタル
- 発売日: 2016/03/22
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
おすすめ度:★★★★★
著者の方を知っているのでひいき目なところありますが、非常に良書。
UXの中のとくにユーザビリティ(Usability)にフォーカスしているのかな
―ユーザエクスペリエンスのための調査、設計、評価手法―")
ユーザビリティエンジニアリング(第2版)―ユーザエクスペリエンスのための調査、設計、評価手法―
- 作者: 樽本徹也
- 出版社/メーカー: オーム社
- 発売日: 2014/02/26
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
おすすめ度:★★★★
UXデザイナーだけでなくプロダクトマネージャーとかが読むべきな本な気もしている
")
Lean UX ―リーン思考によるユーザエクスペリエンス・デザイン (THE LEAN SERIES)
- 作者: ジェフ・ゴーセルフ,坂田一倫,ジョシュ・セイデン,エリック・リース,児島修
- 出版社/メーカー: オライリージャパン
- 発売日: 2014/01/22
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
おすすめ度:★★★★★
UXってかプロダクトマネージャーの本ですが、非常におすすめの名著です!

おすすめ度:★★★★
ユーザーインタビューの具体的な手法をしりたければ一読の価値あり!

ユーザーインタビューをはじめよう ―UXリサーチのための、「聞くこと」入門
- 作者: スティーブ・ポーチガル,安藤貴子
- 出版社/メーカー: ビー・エヌ・エヌ新社
- 発売日: 2017/06/23
- メディア: 単行本
- この商品を含むブログを見る
おすすめ度:★★★
結構読むのしんどい。けど名著 示唆がきっとすごいんだろうなとは思います。

誰のためのデザイン? 増補・改訂版 ―認知科学者のデザイン原論
- 作者: D. A.ノーマン,岡本明,安村通晃,伊賀聡一郎,野島久雄
- 出版社/メーカー: 新曜社
- 発売日: 2015/04/23
- メディア: 単行本
- この商品を含むブログ (6件) を見る
おすすめ度:★★
UX学ぶっていうかこんな会社あるんだ!おもしろ!みたいな文化を考えたい人事や経営者が読むと面白いかもしれない。

発想する会社! ― 世界最高のデザイン・ファームIDEOに学ぶイノベーションの技法
- 作者: トム・ケリー,Tom Kelley,ジョナサン・リットマン,Jonathan Littman,鈴木主税,秀岡尚子
- 出版社/メーカー: 早川書房
- 発売日: 2002/07/25
- メディア: 単行本
- 購入: 44人 クリック: 453回
- この商品を含むブログ (198件) を見る
サイト
先述の誰のためのデザイン? のノーマンパイセンの講座です。
誰のためのデザイン読むの辛いのでこれ見たほうが良いです。
Googleの有名なデザインスプリントに関する授業らしい。次受けようと思っています。
これも面白そうです↓
今Google partnersモバイル広告認定資格試験のための学習ガイドも読んでいるからそのあとかな
メディア一覧
メディアは色々あるのですが、ちょいちょい読もうかなって思っています。
最後に 一緒に何かやりたい、勉強したい、コラボしたい人いたら気軽にメッセとかください!
最後に、色々やってはいるものの実験的にできる環境が常にあるわけではなかったりするものが会社員の常でもあります。
プロフィール - 世界を目指すIT少年の学習記録 にも書いているように
ウェブマーケティングに関することは、全般的にある程度できます。加えてウェブサイト改善とかプロダクト改善やマネジメント、ちょっとした開発なども経験したことがあったりなど、とにかく色々やりたい人間です。
副業の話でも、そうでなくても、勉強したいとかコラボしたいなんでも良いですが、興味を持ったら是非お声掛けください。
連絡はこちらFacebookまたはkenji oda(おだちゃニズム) (@kenji_oda0618) | Twitter
またはブログのコメントでも!
UX勉強し、サイト改善し、サイト作り、最終的にはアマゾンのジャングルでレストラン開業したい!
Deep Learningの基礎を概観しました@ UdacityのDeep learning nanodegree foundation
最近Udacity のDeep learning の一連の講座を卒業したので、その概観の紹介。
そして、理解したこと、まだ理解していないことを自分のために書きます。
そこ違うよ、これ参考になるよとかあれば教えてください!
目次
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
- そもそもUdacity とは?
- UdacityのDeep learning nanodegree foundation とは
- Deep learning とは?
- DL nanodegreeで学んだこと
- 単純パーセプトロンの学習
- TensorFlowの学習
- 畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)
- 再帰型ニューラルネットワーク(RNN: Recurrent Neural Network )とLSTM: Long term short memory
- GAN: Generative Adversarial network
- その他参考になる概念やリンク
- 感想
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
※注 本職はウェブマーケターです(広告、SNS、SEO、ASOなど)何か良い案件(副業など)あれば随時ご相談下さい笑 連絡先はプロフィールへ
データサイエンスは趣味&将来への投資です。Pythonでのウェブアプリ開発とかも少しできるので、他にも何か面白いことあればいつでも紹介してください。基本乗ります。
そもそもUdacity とは?
インターネット上でオープンかつ(ほとんど)フリーのオンライン大学の総称である、Massive Open Online Corses 通称MOOCsの一つです。
他に有名どことしては、edX, Courseraがありますが、Udacityは人工知能の世界的権威の1人であるSebastian Theran が作ったこともあり、データサイエンス系やcomputer scienceが充実しているのが特徴です。
UdacityのDeep learning nanodegree foundation とは
このUdacity はひとつ特徴があります。それはNanodegree というもので、企業などとコラボしてオンラインで取れる学位(みたいなもの)を取得できる一連のプログラムです。
例えばMachine learning nanodegree は最近グーグルに買収されたKaggleとコラボした講座です。さらにUdacityのnanodegree の面白いところは、nanodegree plusというものに申し込むと、卒業後転職まで保証してくれるというプログラムがあるところです。(ただし現状はアメリカ人に限る)
何を言いたいかと言えば、日本の教育のように大学とかで学んでることと社会が求めていることが違うという歯がゆさはなく、学んだことが実世界のスキルに直結する。という点が画期的だと思っています。
Deep learning とは?
知ってるよ!という人は多いと思いますが、簡単に言えば今一番流行ってる人工知能のことです。
ただし人工知能と言っても人間の脳のようになんでもできる万能マシーンではなく、一部のタスクにのみ特化した特化型人工知能です。
わかりやすい例で言えば、囲碁で世界チャンピオンを負かしたAlphaGoとかですかね(あれは強化学習が入ってるので、Deep learning とはまた違うのを組み合わせているようですが)
DL nanodegreeで学んだこと
Deep Learning(以下DL)nanodegree foundationで学んだことは以下の5つのパートに分かれていました。
基本、理論の理解→実装→実践的なプロジェクト
の3本立てで、実践的なプロジェクトはそれぞれレビューがあり、それをすべて合格しないと卒業証書がもらえないという形になっていました。
- 単純パーセプトロンをPythonで初めからコーディング
- TensorFlow(DL用のライブラリ)の学習
- 畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)の理論と実装、画像解析プロジェクト
- 再帰型ニューラルネットワーク(RNN: Recurrent Neural Network )の理論と実装、映画の字幕を自動生成
- GAN: Generative Adversarial Neural networkの理論と実装、人の顔を自動生成
では以下により詳細を説明します。
単純パーセプトロンの学習
単純パーセプトロンとは、ニューラルネットワークのうちの最も単純な形です。
ニールセンの
ニューラルネットワークと深層学習
https://nnadl-ja.github.io/nnadl_site_ja/
の第一章の途中が一番わかりやすいかと思います。

基本的には人の脳のニューロンを模倣しているモデルで、あるインプット(ここでいうX1,2,3)などにたいして、係数をかけ合わせて、その値がある一定の値を超えた時に発火するというモデルです。
例えば、「ある食べ物を食べるか食べないか」(これがOutput)を判断するときに、
甘いもの、辛いもの、酸っぱいものというインプットが与えられているとします。
このときあなたが非常に甘党であれば、甘いものに対しての優先度が非常に高いので、
甘いものという入力に10倍重み付けをするかもしれません。
逆に辛いもの、酸っぱいものはそんなにすきじゃないので、3倍、1倍と掛け合わせます。
すると、甘くて辛いものを見たときには、10+3=13というアウトプットが得られます。
あなたが食べるか食べないかのしきい値が3.5だとすると、13は3.5を超えているので、あなたはその食べ物を食べるという結論を出します。
逆に、酸っぱいもの単体では、足し合わせが1なので、3.5をうわまらないので、食べないという決定を下します。
これが単純なパーセプトロンですね。
output={01if ∑jwjxj≤ thresholdif ∑jwjxj> threshold
output={01if ∑jwjxj≤ thresholdif ∑jwjxj> threshold
誤差逆伝播法(Back propagation)と勾配消失問題(Vanishing gradient problem)
誤差逆伝播法とは何か?の細かい説明は以下のリンクなどを見ればわかるかと思うのですが、簡単にいえば、「ニューラルネットワークの重み付けを効率的に更新していくためのアルゴリズム」です。
重み付けを更新するときに、予測した値と実際の値の誤差=目的関数 を最小化することがニューラルネットワークの目標です。
なぜかといえば、予測した値がなるべく本当の値に近いほうが良いに決まっているからですね笑
そして、この予測と実際の値に差があるときに、それを学習データとして、より良い重み付けを探っていきます。そのときにこの誤差逆伝播を使います。
ただし、誤差逆伝播には問題があり、それが勾配消失問題です。
勾配消失問題とは、重み付けを更新していくときに、アウトプットに近い層は重み付けの更新がうまくいくものが、よりインプットに近い層に進むに従い、うまくいかなくなるという問題です。
これがなぜ起こるのかに関して以下のリンクがうまく説明しています。
誤差逆伝播では、活性化関数の微分を計算します。このとき、活性化関数の種類によって、微分での値が異なります。
例えばシグモイド関数
シグモイド関数は微分を行うと下の図のように、最大で1/4しか値を返しません。
つまり、もし活性化関数にシグモイド関数を使っていると層が進むにつれて、1/4x1/4x1/4… といって重みの更新が非常に小さくなりほとんど学習しなくなります。
これが勾配消失問題です。

それに対して、以下の
Rectified linear unit 通称ReLUは微分するとステップ関数になって重みとしては1を返していきます。ですので層が深くても重みが更新され、勾配消失問題が発生しなくなります。

勾配消失問題と逆で重みが、消失するのではなく、発散してしまうケースもあるとのことですが、その場合明らかに異常値が出てくるのでそこまで問題にはならないようです。
TensorFlowの学習
Deep learning を実装するにあたり、色々なライブラリがあるかと思いますが、Udacity の場合はGoogleが提供しているTensorFlowでした。
そもそもDL以外も色々できるようにしようというコンセプトらしいので、正直僕のようなプログラミング弱者には辛いです笑
本家の畳み込みニューラルネットワークのチュートリアルなどは参考になるかもしれません。
A Peek at Trends in Machine Learning – Andrej Karpathy – Medium https://t.co/mRP4Kmr1Hu
— kenji oda(おだちゃニズム) (@kenji_oda0618) April 17, 2017
Tensorflowなのか世界は Chainerは少ないなぁ pic.twitter.com/QICuavC8T8
ディープラーニングなライブラリは色々あり、それぞれによって特徴が結構違うらしいですが
、世界ではTensorflowが流行りのようです。
日本ではプリファードネットワークが出しているChainerが人気だと思うので、おそらく日本語の資料は多く見つかるのではないでしょうか。そしてChainerは短く書けると聞いたことがあります。
TensorFlowが難しすぎる人にはKerasというライブラリが簡単なのでオススメらしいですが、僕もちゃんと使ったことはないです。
チュートリアル見た感じ簡単そうでしたが。
ディープラーニング実践入門 〜 Kerasライブラリで画像認識をはじめよう! - エンジニアHub|若手Webエンジニアのキャリアを考える! https://t.co/PGuBHiZDdx
— kenji oda(おだちゃニズム) (@kenji_oda0618) May 7, 2017
あとで読む
畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)
畳み込みニューラルネットワークはディープラーニングを一躍有名にしたものだと思いますが、ディープラーニングで特に得意とする画像認識に用いられます。
もともとネオコグニトロンという日本の研究者のモデルをもとにしており、人の脳での視覚野での処理を模倣しています。
詳しくは以下文献が特に参考になりました。
参考になった文献
")
基本的には、画像内の特徴的なパターン(斜め、縦、横など)に反応する層を畳み込み層とします。ここで画像の特徴的なものを抽出します。
次にもう少しざっくりした概念を抽出するプーリング層を挟みます。ここでは、ざっくりとある領域の中で最も大きいピクセルのみに反応する(マックスプーリングの場合)というような処理をするので、畳み込み層で抽出した特徴をもう少しボカすような処理をします。
これが実際脳の視覚野でも同じようなことが行われており、実際プログラミングでもうまく画像認識することが可能になります。
これがざっくりとした畳み込みニューラルネットワークの仕組みです。
再帰型ニューラルネットワーク(RNN: Recurrent Neural Network )とLSTM: Long term short memory
再帰型ニューラルネットワーク通称RNNはその名の通り再帰的な構造を持ちます。
再帰とはウィキによると
再帰(さいき)は、あるものについて記述する際に、記述しているものそれ自身への参照が、その記述中にあらわれることをいう
と書かれています。
つまり自分自身を再度参照するよーってことですね。
これを行うと何が嬉しいかというと、自分の前の状態を参照できる。
それによって「時系列的な影響を考慮できる」というメリットがあります。例えば一個前がこういう状態だったからその値を再帰的に参照して次の時間の状態に引き継ぐことができます。
これがRNNの本質かつ、大きな特徴です。
またRNNをより拡張して特に自然言語処理などに使いやすいと言われているものがLSTMでこれは以下のリンクで美しく説明されています。
Understanding LSTM Networks -- colah's blog
Chat botの作成(Seq to seq)
自然言語処理と言えばチャットボットでしょ。という話があるかと思いますが、LSTMのみで作るとわけわからない文章が生成されたりします。実際映画の字幕から自動で字幕生成するという課題をやったところ結構わけわからないものが出てきました笑
現状は完璧に扱えるものがないので、半分くらい人間が用意した文章をもとにチャットするみたいなSequence to sequence モデルが使われているようです。
※これあんまりよくわかってないから復習する
GAN: Generative Adversarial network
最後にGANをやりました。
先述の
深層学習 (機械学習プロフェッショナルシリーズ)ではCNN, RNNそしてディープボルツマンマシン(DBM)しかなかったので、この講座で初めて知りました。
確かあのBengio先生もニューラルネットワークの中で最も面白い発見の一つみたいに言ってるらしく(確か)確かに今までのものとは違うので面白いです。
僕が解説するよりも以下の記事を読んだ方が圧倒的にわかりやすいですが、特にGANとはなんぞやを説明している文を抜粋すると
この関係は紙幣の偽造者と警察の関係によく例えられます。偽造者は本物の紙幣とできるだけ似ている偽造紙幣を造ります。警察は本物の紙幣と偽造紙幣を見分けようとします。
次第に警察の能力が上がり、本物の紙幣と偽造紙幣をうまく見分けられるようになったとします。すると偽造者は偽造紙幣を使えなくなってしまうため、更に本物に近い偽造紙幣を造るようになります。警察は本物と偽造紙幣を見分けられるようにさらに改善し…という風に繰り返していくと、最終的には偽造者は本物と区別が付かない偽造紙幣を製造できるようになるでしょう。
GANではこれと同じ仕組みで、generatorとdiscriminatorの学習が進んでいきます。最終的には、generatorは訓練データと同じようなデータを生成できるようになることが期待されます。このような状態では、訓練データと生成データを見分けることができなくなるため、discriminatorの正答率は50%になります。
です。このように、ランダムなノイズから生成した画像を本物の画像と同じように偽造していくモデルを構築というのがGAN がやってることです。
詳しくは以下を要参照!
その他参考になる概念やリンク
ハイパーパラメータのチューニング
ハイパーパラメーターとは、重みとかがパラメーターかと思いますが、それよりも前に定義しなければいけない
層数とか層ごとのユニット数などです。
入力と出力はデータや予測したい要素によって決まると思いますが、隠れ層は任意で決めなければいけません。そしてこれは結構めんどくさいです苦笑
友人がハイパーパラメーターの研究してた気がするけど詳細は知りません
転移学習
転移学習(Transfer learning )はめっちゃ便利で、ディープラーニングって学習するのにコンピュータリソースも時間もクソ使うけど、Googleとかが頑張ってチューニングしてくれたやつをそのまま使えまっせってものです。便利だね!
Batch normalization(バッチ正則化)
バッチ正規化はイマイチなんでうまくいくかわかってないけど、とりあえず正則化すると極端な値とかが出てこないから学習しやすいとかだった気がするけど忘れたので勉強します。
Implementing Batch Normalization in Tensorflow - R2RT
Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift
Word2Vec
こちらは自然言語処理系。Bag of wordsのようにある文章内に単語がいくつ出てきたとかではなくて、もっと高度なもので、女王-女=王みたいな計算もできるらしい
どうなってるかよくわかってないからこれも要復習
Word2Vec Tutorial - The Skip-Gram Model · Chris McCormick
最適化関連の手法
最適化でAdam optimizerとか出てくるのでそれなんぞやを解説している
Auto Encoder
これもなぜうまくいくかはよくわからんけどうまくいっている系らしい。
入力と出力を同じようにするよーというもので、ノイズとかがいい感じに減るのかな?なんでうまくいくかは解明されてないのでイメージですが
感想
全体的にディープラーニングを概観できたし、実際の実装や実践的な課題があってめっちゃ良かったです。
値段はこの時ちょっと安くて400ドルくらいだったし、三ヶ月くらいでこんなにできて良かったです。あと卒業証書もこんな感じでもらえるのでLinkedinにも書けるし良いよねー的な笑

けど、当たり前だけどディープラーニングってチューニング大変だし学習データ膨大に必要だったり、画像処理以外は結構実践で使うの大変そうだから、他の初歩的な機械学習アルゴリズムや統計の知識ってやっぱ大事だなと思った次第です。
というわけで、今は初心に帰ってこちらの本

そして、Udacityは
Intro to machine learning
Intro to Machine Learning Course | Udacity
Model building and validation
Model Building and Validation | Udacity
の二つをやってます。
引き続き頑張ろう!
Deep Learningをやっている。 1,2,3月振り返り
月一で更新する予定が全然できていなかった笑
Deep Learningを真面目にやっている
掲題の通り、最近はDeep Learningをやっている。
なぜやっているかといえば、
UdacityのDeep Learning nanodegree foundationというプログラムに参加しているからである。↓
なぜ入ったかというと、単純にプログラム内容が魅力的だったからである。
だって、画像認識とかは当たり前だけど、
映画のセリフをDeep Learningで自動生成、翻訳、音楽生成とかめっちゃ楽しそうやん!!!
ただそんだけ。あとやっぱ知っておいたほうが良いかな的な
主に、Tensorflowでの実装ですね。その前にもPythonで簡単なパーセプトロンでの3層構造くらいのNNは実装しました。
誤差逆伝播法(Back propagation)とかはふーーんくらいに思っていたけど、きちんと理解しておかないとどの活性化関数を選ぶべきかとか、勾配消失問題とかが理解できなくなるので大事だなと思います。
ちなみにこれについて載っているサイトはこれです↓
※最近Mediumはまじめな記事が充実しているんですね。
あとRNNのLSTMをめっちゃわかり易く説明しているリンクが下記です。おすすめ
Understanding LSTM Networks -- colah's blog
学んだことをただまとめるサイトを作り始めた
上記のリンクのように、コースをやっている中で外部リンクが紹介されることが多いので、それをどうやって管理しようかなぁという問題があったのでメモがてらで、リンクを集めるサイトを作った。(Google siteだけどね)
あとは、自己学習時におけるハードルって結構色々あると思っていて、自分も過去&現在でその課題を感じているので、何かしらの方法で解決できないかなを模索しようという意思もあり、実験的に作り始めた。
それが以下である。
である。(これは普通に便利だと思います。英語多いけど)
他にも勉強したこと&していること
3ヶ月分あるからざっくりでいいやw
本
もっと詳細な理論とか知りたいなと思って読んだ。完全には理解していない部分もあるw DBMとか。でもCNNやRNNの理解には役に立ったなぁ
")
馬田さん本。最後の章が一番おもしろかった
")
他にも色々読んだ気がするけど忘れたからいいやw
オンライン講座
データをいかに取得し加工するかという話。前処理ってやつですかね。データサイエンスの8割はこの作業に時間を費やされるとか。大変ですな。まだ、落とし込めている感が一ミリもないから、もう一回復習しようかなって思っている
今やっているなうだけどSklearnを主に使って、基礎的な機械学習が学べる、SVM, Naive bayes, Decision treeとかさ。Sklearn使うとマジ簡単だねw
基礎的なやーつ 大事だね。Siraj(Youtuberでデータサイエンスの面白いやつ)っていうやつのおすすめ
結論
独学は頑張ればすべてオンラインで完結する。
お金も必要じゃない。
けど、まだまだハードル高いから解決する何かを作りたい
それが Academic Wiki が目指すところ。
P.S.
Kaggleやりたい。やります。